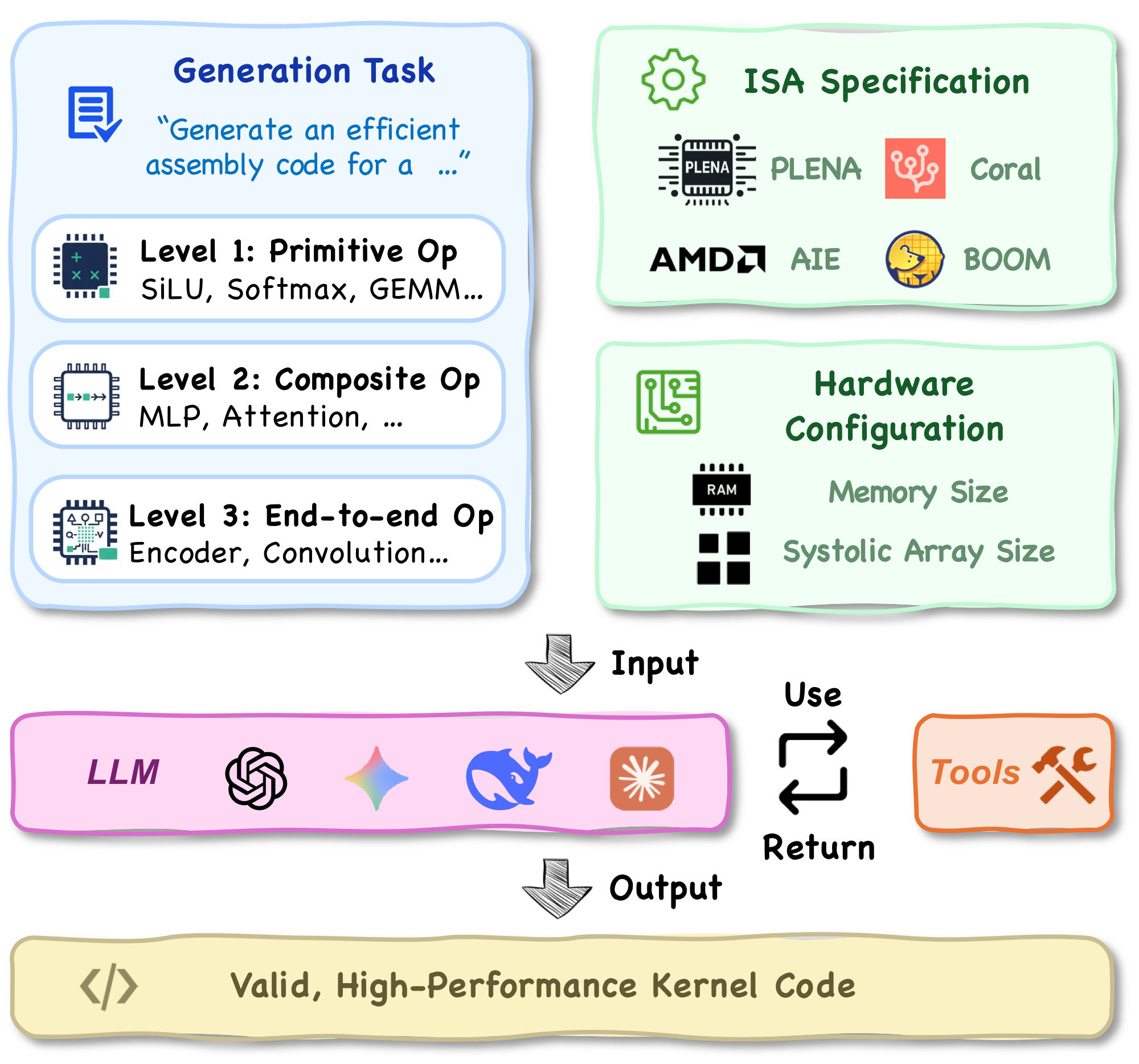
New AI accelerators with novel instruction set architectures (ISAs) often require developers to manually craft low-level kernels — a time-consuming, laborious, and error-prone process that cannot scale across diverse hardware targets. This prevents emerging hardware platforms from reaching the market efficiently. While prior LLM-based code generation has shown promise in mature GPU ecosystems, it remains unclear whether agentic LLM systems can quickly produce valid and efficient kernels for emerging hardware with new ISAs.
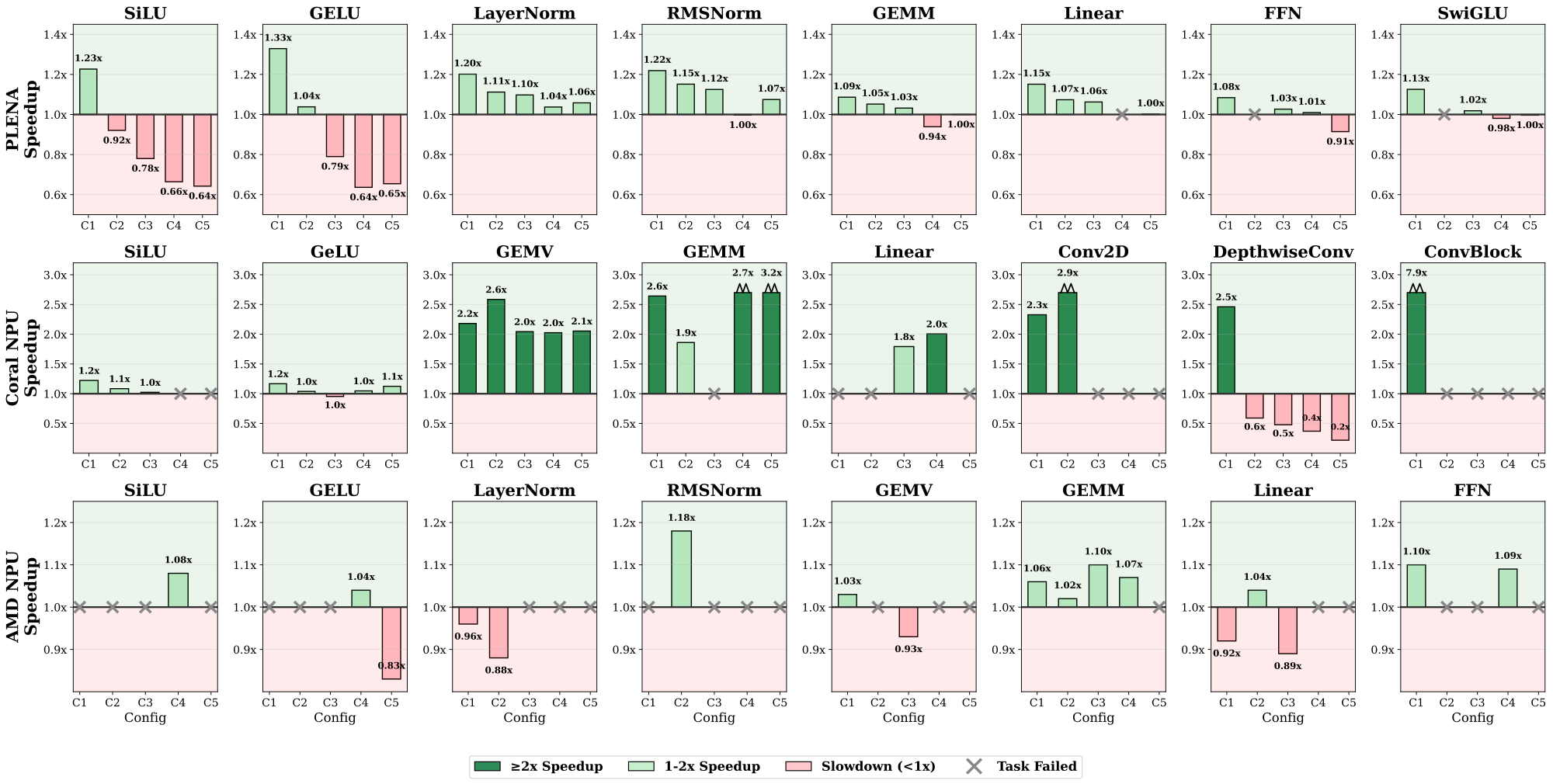
We present KernelCraft: the first benchmark to evaluate an LLM agent's ability to generate and optimize low-level kernels for customized accelerators via a function-calling, feedback-driven workflow. Within KernelCraft, the agent refines kernels under ISA and hardware constraints using automated feedback derived from compilation checks, simulation, and correctness validation against ground truth. In our experiments, we assess agent performance across three emerging accelerator platforms on more than 20 ML tasks, each with 5 diverse task configurations, with special evaluation of task configuration complexity. Across four leading reasoning models, top agents produce functionally valid kernels for previously unseen ISAs within a few refinement steps, with optimized kernels that match or outperform template-based compiler baselines. With that, we demonstrate the potential for reducing the cost of kernel development for accelerator designers and kernel developers.